이세돌 9단의 충격적인 2연패 이후 알사범 '알파고'에 대한 관심이 높아지고 있습니다. 그리고 알파고는 과연 어떤 방식으로 동작하는지 궁금해하는 분들도 많아지고 관련 기사와 자료들이 공유되고 있습니다. 아래 글은 현재 서울대 컴공과에 재학중인 김범수 군이 쓴 글입니다. 많은 분들이 읽어보기를 바라며 본인에게 허락을 받고 트렌드와칭에도 공유를 합니다. 원제목은 "AlphaGo Pipeline 헤집기"입니다.
주변에서 알파고 열풍이 불고 있는데, 실제로 알파고가 어떤 방식으로 동작하고 있는지 이해하면서 알파고에 대한 이야기를 하는 분들이 그렇게 많은 것 같지는 않았습니다. 조금이라도 보다 많은 분들이 알파고 및 인공지능에 대해 이해하실 수 있도록 알파고가 어떤 방식으로 작동하는지 제일 기본적인 부분에서부터 나름대로 정리해보았습니다. 딥러닝이나 인공지능 같은거 모르셔도 충분히 읽고 어떻게 돌아가는지 이해하실 수 있을거예요.. 아마... ㅎㅎ 재미있게 읽어주시고 도움이 되는 것 같으면 공유도 해주시고, 틀린 점 있으면 지적도 해주세요!
들어가기
주위에서 온통 알파고(AlphaGo) 이야기만 들려온다. 글을 쓰기 시작한 3월 11일 현재 알파고는 이세돌 九단과의 경기를 두 경기 진행한 상태이다. 대결 시작 전 이세돌 구단이 5:0으로 무참히 이겨버릴 것이라는 여론과는 다르게 두 경기 모두 불계승으로 상대를 꺾은 알파고는 전 세계 모든 바둑인들을 경악시켰다. 앞으로 남은 경기들에 어떤 결과가 나올지는 모르지만 현재까지 나온 결과만으로도 알파고는 인공지능 역사에 길이 새겨질 큰 족적을 남기고 있다.
알파고가 등장하기 전까지 바둑은 컴퓨터가 인간을 범접할 수 없는 유일한 아날로그 게임이라고 여겨졌다. 실제로 지금까지 개발되어온 바둑 AI들은 프로의 기력을 넘보기에는 실력 차이가 너무나도 컸다. 그렇다면 알파고는 도대체 어떤 방법을 사용했기에 기존의 알고리즘과 엄청난 실력차를 보이고 심지어 세계 정상급의 프로 기사까지 꺾을 정도의 실력을 갖출 수 있었을까? 알파고의 놀라운 실력을 파헤쳐보기 위해 이제부터 알파고라는 프로그램이 어떤 방식으로, 그리고 어떤 구조로 바둑이라는 게임에 접근했는지 그 과정을 세세하게 짚어보도록 할 것이다.
일반적인 AI 전략
알파고 자체의 구조에 대해 말하기에 앞서 1:1 대결 형식의 보드 게임 인공지능들이 대략적으로 어떤 방식을 통해 문제에 접근하는지부터 논의해보고자 한다.
우리가 만약 시간제한을 고려하지 않고 무한대의 시간이 걸려도 좋으니 보드게임에 승리하는 인공지능을 만들어달라는 의뢰를 받았다고 해보자. 시간 제한이 없는만큼 가장 이상적인 방법은 ‘현재 상태에서 가능한 행동들을 전부 고려하면서 최대한 먼 수까지 바라보고 그 중 가장 이상적인 행동을 취하는 것’이다. 문제는 바둑과 같은 1:1 대결 형식의 보드게임은 내가 어떤 행동을 취할 경우 상대방의 기회가 돌아가고 상대방도 자신이 이득이 되는 행동을 한다는 것이다. 결국 내가 어떤 행동을 취했을 때 상대방이 어떤 행동을 할 것인지도 고려하면서 앞의 수를 바라보아야 한다.

다음과 같은 행동트리를 살펴보자. 동그라미 친 부분이 내가 둘 차례이고, 네모를 친 부분이 상대가 둘 상태이다. 나와 상대가 할 수 있는 행동들을 전부 고려해보았을 때, 4수 뒤에 내가 얻을 수 있는 점수가 ‘4’ 층에 표시되어 있다. 이 점수중 내가 얻을 수 있는 가장 큰 점수는 +무한대 점수이고, 나는 이 점수를 얻을 수 있으면 정말 좋을 것이다.
그러나 당연히 합리적인 상대라면 내가 얻을 수 있는 점수를 최소화하는 방향으로 행동을 할 것이고 따라서 +10, +무한대 중 더 작은 +10 점수를 얻게 만드는 행동을 할 것이다. 또한 내 차례일 경우 나는 내 점수를 최대화하는 행동을 선택할 것이다. 이러한 생각을 가지고 4층부터 0층까지 올라가다 보면 결국 내가 취해야할 행동은 4층의 점수들 중 가장 높은 점수인 +10이나 +무한대 등을 얻기 위한 왼쪽 길이 아니라 상대의 행동까지 고려해보았을 때 가장 높은 점수인 ‘-7’ 을 얻기 위한 오른쪽 길을 선택해야한다는 것을 알 수 있다.
바둑과 같은 1:1 대전 게임에서 이러한 방식으로 행동을 하는 것은 가장 이상적인 행동 선택 방법으로 알려져 있으며 상대방이 제공하는 최악의 수들 중 가장 최선의 수를 선택해야한다 는 의미에서 이를 minimax 알고리즘이라고 한다.
minimax 알고리즘이 가장 이상적인 행동 양식이라면 우리의 의뢰를 해결하기 위해서는 최대한 많은 경우의 수를 고려하고 그 중 minimax 알고리즘에 의해 가장 이상적인 행동을 취하는 프로그램을 만들면 된다! 우리의 의뢰는 해결되었다. 그러나 현실세계에서 이를 적용하기는 힘들다. 왜냐하면 몇 수 앞을 내다보냐에 따라 고려해야할 상태의 가짓수가 기하급수적으로 늘어나기 때문이다.
예를 들어보자. 바둑의 경우 돌을 놓을 수 있는 칸의 갯수가 총 361개이다. 계산을 위해 수를 예쁘게 만들어서 한 상태에서 행할 수 있는 행동이 대략 300개라고 해보자. 그렇게 할 경우, 상대방의 수까지 합해서 총 6수 앞까지 고려할 경우 고려해야할 총 가짓수는 300^6= 729000000000000 (729조 개)이다. 애석하게도 컴퓨터의 연산 능력에는 한계가 있기 때문에 이 정도로 많은 상태의 수를 다 고려하고 계산하기 위해서는 1초에 1억개의 상태를 계산한다고 해도 세 달 정도의 시간이 걸린다.
물론 이 가짓수는 몇 수 앞을 내다보냐에 따라 지수적으로 늘어나기 때문에 체스나 바둑같은 거대한 보드게임에서 minimax 알고리즘만을 가지고 유의미한 능력의 인공지능을 만들기란 사실상 힘들다. 보통 프로 기사들은 50수 앞까지 내다보면서 대국을 한다고 하는데 minimax 알고리즘으로 50수 앞까지 내다본다면? 태양이 수명을 다해서 식을 때까지 계산해도 답을 못 낼 것이다.
결국 강력한 인공지능을 만들기 위해서는 이러한 탐색 공간을 효율적으로 탐색하면서 시간을 덜 사용함과 동시에 minimax 알고리즘에 가까운 성능을 내는 행동을 찾는 새로운 알고리즘이 필요하다. 이러한 방법을 찾기 위해 Alpha-beta Pruning, Principal variation search 등 다양한 방법들이 제시되었는데, 이제부터 소개할 방법은 그 중 보드게임 관련 인공지능에 가장 많이 사용된, 그리고 알파고가 기반으로 하고 있는 '몬테카를로 트리검색 Monte Carlo Tree Search (MCTS)' 라는 방법이다.
몬테카를로 트리검색
몬테카를로 (Monte Carlo)라는 방식은 ‘확률적인 방식을 이용하여 문제를 해결하는 방법’ 들을 총칭하는 말이다. 이 방법에서는 실제로는 구하기 힘든 정교한 식이나 실제로 다 보기 힘든 거대한 탐색 공간에 대해 직접적으로 접근하는 대신 ‘랜덤’ 을 이용해서 근사적으로 접근한다. 예를 들어 2 x 2 짜리 정사각형에 내접하는 반지름 1짜리 원을 그려넣고 이 정사각형 안에 무작위로 점을 찍어서 원 안에 들어간 점의 수 / 전체 찍은 점의 수를 계산한다고 해보자. 점을 무진장 많이 찍다보면 그 값은 결국 π/4 의 값으로 수렴하게 될 것이다. 이것이 전형적인 몬테카를로 방법의 예시로 몬테카를로를 이용하여 원주율의 값을 계산하는 방법이다.
Monte Carlo Tree Search (MCTS)는 앞서 말한 minimax에서의 행동 트리를 탐색하는 과정에서 몬테카를로 기법을 적용하여 굳이 모든 상태에 대해 찾아보지 않고서도 좋은 행동을 선택할 수 있도록 설계된 알고리즘이다. MCTS가 어떤 방식으로 랜덤을 사용하여 트리를 구성해나가는지 가장 기본적인 MCTS의 형태를 살펴보자.
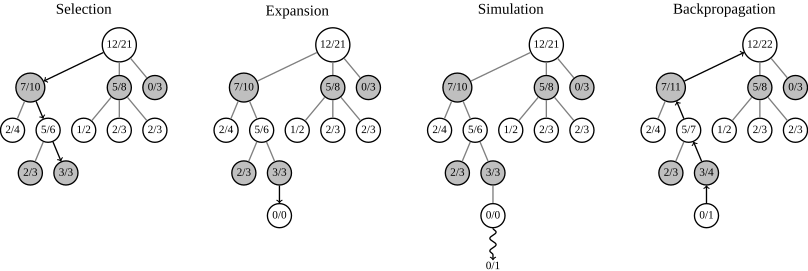
Monte Carlo Tree Search Diagram. 출처:Wikipedia
MCTS의 기본적인 스텝은 총 4가지 단계로 이루어져 있다.
Selection : 루트로부터 시작하여 자식 중 가장 성공적인 자식을 택하는 방식으로 Leaf Node까지 이동한다. 일반적으로 한 쪽으로만 탐색이 몰리는 것을 방지하기 위해 여기에 랜덤하게 벗어날 여지를 주는 식으로 보정한다.
Expansion : 리프 노드에 도달했는데 이 리프 노드가 게임을 끝내는 단계의 최종 노드가 아닐 경우 다음 단계의 자식 노드를 생성하고 그 중 하나의 자식을 택하여 이동한다.
Simulation : 현재 상태에서 랜덤하게 시뮬레이팅을 해서 게임을 진행해본다. 이를 playout이라고 하는데 게임을 끝까지 진행해서 내가 이기는지 지는지에 대한 결과값을 얻는다.
Backpropagation : 현재 진행한 시뮬레이션의 결과를 바탕으로 내가 온 경로들의 노드들에 결과값을 업데이트 해준다.
MCTS 에서는 이러한 단계를 최대한 많이 반복하여 내가 택할 수 있는 행동들에 대해 각 행동이 어느 정도의 승률을 불러올까에 대한 정보를 시뮬레이팅 한다. 어느 정도 탐색을 하여 최종적으로 나의 행동을 선택해야 할 때는 루트에서 할 수 있는 행동들 중 가장 많이 택하여 시뮬레이션을 해본 행동을 선택한다. 놀랍게도 이러한 MCTS를 무한정 반복할 경우 결과값이 minimax의 결과로 수렴한다는 사실이 증명되어 있다. 그러나 일반적으로 기본적인 MCTS의 수렴 속도는 굉장히 느리기 때문에 탐색 공간을 줄이고 효율적으로 결과를 찾아내기 위한 방법이 필요하다.
MCTS에서 수렴을 통해 얻고자 하는 최종적인 결과는 트리에 있는 각 노드 (게임의 상태)에서 ‘내가 이길 확률이 얼마나 되는지’이다. 이에 대해 현재 게임의 상태 s가 주어졌을 때 이 상태에서 내가 게임에서 이길 수 있는 확률의 정도를 계산하는 이론적인 함수 v*(s) 가 있다고 쳐보자. 물론 우리가 이러한 함수가 실제로 어떤 모양이고 어떻게 작동하는지는 알 수 없지만 이런 함수의 존재를 가정해볼 수는 있다. MCTS를 무한정 진행할 경우 MCTS의 각 노드의 값들은 각 상태에서의 이론적인 승률 계산 함수값 v*(s) 의 값에 수렴하게 된다.
이를 역으로 접근해보면 v*(s)를 근사할 수 있는 함수 v(s)가 존재한다면 우리가 MCTS를 통해 얻고자 하는 결과를 먼저 근사적으로 얻을 수 있기 때문에 MCTS를 깊게 진행하지 않더라도 우리가 원하는 이상적인 행동을 계산할 수 있을 것이라는 생각을 할 수 있다. 또한, 이러한 함수를 조금 수정한다면 ‘현재 상태에서 어떤 행동을 하는 것이 더 좋을지’에 대한 값들도 얻어내어 MCTS 트리에서 가지치기를 할 때 더 효과적인 가지부터 칠 수 있게 하는 역할도 할 수 있을 것이다. 즉, 현재 게임의 상태 s로부터 내가 이길 수 있는 정도를 계산하는 함수 v(s)를 잘 만들어내는 것이 중요한 문제로 대두된다.
기존의 연구자들도 MCTS와 v(s)를 이용한 방법까지는 접근했고 이를 이용하여 Pachi나 Fuego 등의 바둑 AI 들이 만들어졌다. 그러나 v(s)라는 함수 자체가 너무나도 만들기 어려운 함수이기 때문에 기존의 연구들은 강력한 v(s) 함수를 만드는 데에 실패했고 결국 이러한 한계는 AI 성능의 약화로 이어질 수밖에 없었다. 그러나 이 시점에서 구글의 딥 마인드 팀은 v(s)를 만드는 데에 딥 러닝을 접목시켜 성능을 크게 향상시킨다.
딥러닝 : 개요
딥 러닝은 ‘인공신경망’ 이라는 구조를 골자로 하고 있는 학습 알고리즘이다. 인공 신경망은 말 그대로 인간의 뇌에서 뉴런들이 연결되어 있는 신경들의 망을 수학적으로 간단히 모델링하여 모방한 구조를 말하는데, 대략적인 구조는 다음과 같다.

인공신경망. 출처:Wikipedia
그림에서 동그라미 쳐져있는 부분들은 각각 하나의 ‘노드’ (인간의 뉴런 하나를 모방한 것이다) 이며 자신에게 들어오는 인풋값들을 바탕으로 값을 하나씩 계산해내고 이 값을 다음 층의 노드들로 넘겨준다. 이것이 반복되며 마지막 층까지 값이 전달되고, 이 값이 내가 원하는 값이 되도록 인공 신경망을 학습시켜주어야 한다. 이 때 각각의 화살표에는 ‘weight’ 라고 해서 시작 값에 얼마의 값을 곱해서 다음 노드에 넘겨줄 것인지에 대한 가중치가 있다. 인공 신경망을 학습한다는 것은 이러한 weight들을 조절하여 신경망이 우리가 원하는 값들을 내놓도록 조정하는 것을 의미한다.
인공 신경망은 처음에는 아무런 정보도 가지고 있지 않기 때문에 처음 계산을 시키면 정말 의미없는 값들만 뱉어낼 것이다. 이를 학습시키기 위해서는 실제로 어떤 인풋이 주어졌을 때 어떤 아웃풋이 주어져야 한다, 라는 데이터들이 필요하다. 이 데이터의 인풋을 신경망에게 입력시켰을 때 뱉어내는 결과와 실제 결과를 비교하여 얼마나 차이나는지 계산을 하고 이 차이에 대해 기울기(미분값)를 이용하여 각 weight들을 조금씩 움직이는 ‘gradient descent’ (기울기 강하) 방법을 이용하여 신경망을 학습시킨다. 수많은 데이터를 이용해 계속 weight를 움직여줄 경우 신경망은 결국 우리가 바라는 바를 학습할 수 있다.
이러한 인공 신경망 모델은 한 때 거대한 난항을 겪었는데, 그림에 나와있는 형태같은 3층의 신경망은 학습할 수 있지만 그보다 큰 신경망을 제대로 학습시킬 수가 없었던 것이다. 신경망은 노드의 수가 많고 층이 깊어질 수록 표현하고자 하는 함수를 보다 순조롭게 학습할 수가 있는데 층을 깊게 늘릴 경우 weight를 조절하기 위한 기울기가 층을 거쳐오면서 사라졌고 이에 따라 제대로 학습이 진행되지 않는 문제들 때문에 그 성능이 제한되었었다.
또한, 인공 신경망의 층 사이에서 값을 전달하기 위해서는 weight와 입력값을 곱해주기 위한 행렬연산이 필요하다. 그러나 노드의 수가 많아지면 이러한 행렬연산의 계산복잡도가 너무 높아져 빠르게 학습을 진행할 수가 없었다. 그러나 시간이 지나면서 이러한 학습 방법을 개선할 수 있는 방법들이 만들어지고, 병렬적인 계산을 통해 행렬 곱셉에 최적화된 GPU 분야의 개발이 가속화되면서 신경망의 크기와 깊이를 키울 수 있게 되었다. 이러한 거대한 신경망을 다루어서 문제를 해결하는 것이 결국 ‘딥 러닝’ 으로 불리는 분야로 떨어져 나온 것이다.
딥 러닝 분야가 발전하면서 기존의 단순한 계층 구조의 신경망 뿐만 아니라 여러 다양한 형태의 입력에 적용시킬 수 있는 새로운 신경망 구조들이 개발되었다. 그 중 하나가 알파고가 사용하고 있는 Convolutional Neural Network (CNN) 이다.
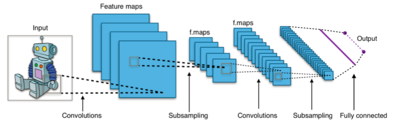
Convolutional Neural Network. 출처 : Wikipedia.
기존의 네트워크가 일차원의 벡터의 형태로 입력을 받던 것과 달리 CNN에서는 보통 2차원의 형태로 입력이 주어진다. 예를 들어 30 x 30 크기의 이미지가 입력으로 주어진다고 해보자. 이러면 CNN의 ‘Convolution Layer’ 라는 층에서 이 이미지를 구석구석 살펴보면서 새로운 값을 만들어낸다. Convolution Layer에는 일정 크기의 ‘window’ 라는 것이 존재한다.
이 window가 3 x 3의 크기라고 해보면, convolution layer에서는 이미지에서 가능한 모든 3 x 3 크기의 작은 부분들을 살펴보면서 각각의 부분의 weight를 곱하여 새로운 값을 만들고 이 값들이 모두 모여 새로운 28 x 28 크기의 아웃풋을 만들어낸다. 이러한 과정을 거쳐나가면서 CNN은 이미지에서 자신만의 기준으로 ‘특징’ 을 추출해 내는 방법을 학습하게 되고 이러한 특징들을 가지고 마지막에 기존의 계층적 인공신경망과 유사한 층을 연결하여 원하는 결과를 내보내도록 학습을 하게 된다. CNN도 기존의 인공신경망과 마찬가지로 입력값과 이에 따른 정답값이 있으면 유사한 방법으로 gradient descent를 적용하여 weight들을 학습해나갈 수 있다.
눈치가 빠른 독자라면 여기까지의 설명만으로도 CNN 구조가 알파고에 어떻게 적용되었는지 유추할 수 있을 것이다. 바둑판의 경우 가로, 세로로 각각 19개의 줄이 있는 격자판 형태의 모습을 가지고 있다. 즉, ‘현재 바둑판의 상태를 19 x 19 크기의 이미지처럼 표시할 수 있는 것’ 이다. 알파고는 이 점을 이용하여 바둑판의 상태를 이미지처럼 입력해주면 이 값을 CNN에 넣으면 원하는 값 즉 현재 상태가 나에게 얼마나 유리한 상태인지 그리고 현재 상태에서 돌을 어느 자리에 넣는지가 유리한지 등을 계산하는 네트워크를 만들어서 학습하였다. 결국 알파고는 기존의 이론으로는 만들어내기 힘들었던 v(s)라는 함수를 딥 러닝 기법을 이용하여 매우 효과적으로 만들어낼 수 있었던 것이다. 이것이 기존의 바둑 AI와 알파고의 가장 큰 차이점이다.
알파고 파이프라인 구조
지금까지의 설명을 통해 알파고가 MCTS 기법, 그리고 딥 러닝을 이용해 학습한 상태 평가 함수 v(s)를 이용하여 효과적으로 상태-행동 트리를 탐색해나간다는 것을 알게 되었다. 그러나 실제 알파고 내부는 지금까지의 설명보다 훨씬 복잡한 방식으로 계산이 이루어지고 있으며 신경망도 하나가 아니라 여러 개가 있어 각각을 보완하는 구조로 이루어져 있다. 실제 알파고 내부의 신경망들이 어떤 식으로 이루어져 있는지 먼저 대략적으로 살펴보자.
![AlphaGo Network Structures. 출처 : [1]. (알파고 논문)](https://shuuki4.files.wordpress.com/2016/03/alphago-networks.png?w=1000)
AlphaGo Network Structures. 출처 : [1]. (알파고 논문)
먼저 알파고에는 ‘현재 상태에서 다음에 놓여질 돌의 위치를 예측하는’ (즉, 현재 상태에서 상대가 돌을 놓을 위치를 예측할 뿐만 아니라 내가 어디에 놓아야할 지도 예측할 수 있는) 네트워크가 있다. 논문에서는 이를 ‘policy network’ (정책망) 이라고 한다. 물론 CNN의 형태를 가지고 있다.
Policy network를 학습하기 위해 알파고는 먼저 방대한 양의 데이터가 필요했다. 앞서 살펴보았듯이 CNN을 학습시키기 위해서는 ‘인풋 데이터’ 와 이에 대응하는 ‘해답’ 이 굉장히 많이 필요했는데 이를 KGS라고 하는 바둑 사이트에 남아있는 기보들을 사용하였다. 이 기보들을 사용해서 총 3천만개 정도의 ‘돌 상태가 주어졌을 때, 다음에는 어디에 놓을지’ 에 대한 데이터가 확보되었고 이를 이용하여 policy network를 학습하였다. 또한, 차후 MCTS에서 이용하기 위해 policy network보다는 부정확하지만 훨씬 빠르게 같은 문제를 계산할 수 있는 ‘Rollout policy’ 라는 네트워크도 준비하여 학습시켰다.
알파고는 이에 그치지 않고, 이 네트워크를 더욱 더 발전시켰다. 일반 사용자들이 둔 대전을 이용하여 학습한 네트워크의 성능은 그 사용자들의 수준을 크게 상회하기는 어려울 것이다. 이를 방지하기 위해, 알파고는 ‘과거의 자신과의 대결’ 을 통해 더욱 학습을 진행했다. 과거의 자신과 대결하여 대결에서 이겼을 경우 현재 사용하는 네트워크의 weight를 강화시키는 방향으로 나아가고 졌을 경우 그 반대 방향으로 나아가는 방법을 이용하여 네트워크의 성능을 향상시켰다.
그 결과 기존의 KGS 데이터만을 이용한 네트워크보다 더 높은 정확도를 가진 네트워크를 완성시킬 수 있었다. 이 네트워크를 이용하면, 위 그림의 오른쪽
Policy network도 대단한 네트워크이다. MCTS를 이용하지 않고 policy network만을 이용하여 단순히 돌을 놓았을 때에도 기존의 바둑 AI들을 높은 승률로 이길 수 있었다. 그러나 네트워크만으로는 진정한 알파고를 구동시킬 수 없다. 앞서 살펴보았듯이 MCTS 탐색을 위해서는 현재 돌이 놓여있는 상태에서 플레이어가 이길 정도를 계산하는 v(s)가 필요하고, 이를 계산하는 네트워크를 ‘value network’ (가치망) 이라고 한다.
Value network의 경우 policy network와 유사한 CNN 구조를 가지고 있다. 그러나 policy network가 마지막에 모든 돌을 놓을 수 있는 자리에 대해 확률 분포를 계산하는 것과 달리 value network는 마지막에 인풋으로 주어진 상태 s에 대한 단순한 값 하나만을 내놓는다. 이 네트워크를 학습시키기 위해 알파고는 ‘자신과의 대결’ 에서 나온 기보 데이터들을 저장해 놓은 뒤 이기는 상태와 지는 상태들을 모아 value network의 학습 데이터로 넣어주었고 성공적으로 학습을 마칠 수 있었다.
![AlphaGo MCTS. 출처 : [1].](https://shuuki4.files.wordpress.com/2016/03/alphago-mcts.png?w=1000)
AlphaGo MCTS. 출처 : [1].
알파고는 앞서 만든 Policy Network와 Rollout Policy 그리고 Value Network를 사용하여 MCTS를 진행한다. 각각의 네트워크는 다음과 같은 방식으로 이용된다.
Policy Network : 본래 Selection 단계에서 MCTS는 가장 성공적인 자식 노드를 선택하는 방법을 사용한다. 그러나 알파고의 MCTS는 여기에 Policy Network에서 계산한 ‘현재 state에서 이 돌을 놓을 확률’ 에 대한 항을 더하여 더 높은 확률을 가진 행동 쪽으로 더 많이 움직이게 하는 방식을 차용한다. 이것은 기존의 컴퓨터 알고리즘이 구현하지 못했던 인간만의 ‘직관’ 을 알파고가 나름대로의 방법으로 구현했다고 해석할 수도 있다. 또한 탐색이 너무 한쪽으로 몰리는 것을 방지하기 위해 한 행동을 너무 많이 방문하면 어느 정도의 패널티를 주어 다른 방향의 행동에 대해서도 탐색을 해보도록 장려하기도 한다.
Rollout Policy : Rollout policy는 policy network보다는 성능이 훨씬 낮지만, 훨씬 빠른 계산을 할 수 있다는 장점을 가지고 있다. 따라서, MCTS의 Evaluation 단계에서 시뮬레이션을 돌릴 때 이 rollout policy 네트워크를 사용하여 시뮬레이션을 진행한다.
Value Network : Value network는 마찬가지로 Evaluation 단계에서 사용된다. Evaluation 단계에서는 rollout policy와 value network를 이용한 점수를 둘다 구하고 둘을 일정 비율로 더하여 이 state의 최종적인 점수를 계산한다. 논문에 의하면 Rollout policy와 value network 를 하나씩만 사용하는 것보다는 (Single Machine에서 각각 ELO Rating 2450, 2200 정도) 둘을 복합적으로 사용하여 점수를 더해주는 것이 훨씬 좋은 결과를 내었다 (ELO Rating 2900 정도).
각 과정 중 selection, expansion, evaluation의 과정을 마치면 선택한 state에 대해 evaluate 한 점수 V(s) 가 나온다. 이 점수를 이용하여 backup 과정에서 방문한 경로의 점수와 방문한 횟수를 업데이트 해주고, 일정 시간동안 갱신을 한 후 갱신이 끝나면 최종적으로 현재 선택할 수 있는 돌의 위치 중 MCTS 트리에서 가장 많이 방문한 돌을 선택하여 놓게 된다.
앞서 설명한 MCTS 트리를 갱신해나가는 과정은 다행히도 연산을 분산시켜서 진행할 수 있는 과정이다. 따라서 알파고는 마지막 발전으로 하나의 컴퓨터에서 계산을 진행하는 대신 여러 개의 CPU와 GPU로 연산을 분산시켜서 MCTS를 수행하였고 그 결과 프로들도 이해할 수 없는 ‘신의 한 수’를 찾아내는 정도의 탐색 능력을 가진 인공지능이 되었다
마치며...
지금까지 알파고가 대략적으로 어떤 방식으로 좋은 수를 탐색하는지를 알아보았고, 이를 알아보기 위해 기초적인 부분부터 차근차근 살펴보았다. 알파고 내부의 각각의 layer가 정확하게 어떤 구조로 설계되었고, 어떤 방식으로 학습되었는지에 대한 자세한 한글 설명은 이 블로그를 확인하면 좋을 것 같다. 각각의 레이어의 구조와 목적 함수, 성능 등에 대한 설명이 자세하게 되어있다. 이 보다 더욱 자세한 설명을 원하시는 분들은 Nature에 실린 알파고 논문을 한번 읽어보시면 좋을 것 같다. 자세한 실험 과정 및 학습 방법이 상세하게 서술되어 있다.
일각에서는 이미 알파고를 ‘AI가 인간을 지배할 대 인공지능 시대의 서막’ 정도로 서술하고 있다. 많은 사람들이 알파고가 인류 최강 바둑기사를 박살내는 모습에 인공지능에 거부감을 가지거나 공포를 느끼고 심지어는 삶의 무력함을 느끼는 분들도 실제로 계신다고 들었다.
그러나 머신러닝과 인공지능은 다른 방면에서 보면 ‘인간이 할수 없는 일을 해냄으로써 인간의 생활을 극도로 발전시킬 수 있는’ 존재이다. 미국 퀴즈 프로그램 Jeopardy에서 다른 쟁쟁한 경쟁자들을 제치고 우승한 슈퍼컴퓨터 ‘Watson’ 은 현재 의료분야에서 사용되어 의사보다 훨씬 높은 정확도로 암을 진단하는 데에 쓰이고 있다. 보다 일생생활에 밀접한 예시를 들어보자면 머신러닝을 이용한 수많은 자동운전 차량들이 활발하게 연구되고 있다. 이러한 자동운전 차량들은 인간의 삶을 윤택하게 해줄 뿐만 아니라 높은 교통사고율까지 효과적으로 줄여줄 수 있는 것이다.
지피지기면 백전백승이라는 말이 있다. 인공지능과 머신러닝의 능력이 급등하고 있는 이 시점에서 단순히 감탄하거나 놀라워하기보다는 ‘이들이 어떤 방식을 차용하기에 기존에는 불가능할것만 같았던 일을 해내는지’, ‘어떻게 하면 이들을 다룸으로서 내가 직면한 문제를 해결할 수 있는지’에 대해 공부한다면 지금 불어오고 있는 머신 러닝의 바람에 올라타 더 높은 곳을 바라볼 수 있을 것이라고 믿는다.
참고자료
[1] D. Silver et al. “Mastering the game of Go with deep neural networks and tree search.” Nature 529.7587 (2016): 484-489.
주변에서 알파고 열풍이 불고 있는데, 실제로 알파고가 어떤 방식으로 동작하고 있는지 이해하면서 알파고에 대한 이야기를 하는 분들이 그렇게 많은 것 같지는 않았습니다. 조금이라도 보다 많은 분들이 알파고 및 인공지능에...
Posted by Kim Beom Su on Friday, March 11, 2016
서울대 컴공과 학생인 김범수 군의 글을 우연찮게 보게되었는데 내용 정리가 아주 잘(?) 되어 있어 소개해 드립니다. 내용을 모두 이해하진 못했지만 최근 이슈를 자신의 전공분야로 잘 정리한 멋진 글입니다. 앞으로 트렌드와칭에서 또 소개할 수 있길 기대합니다. ^^
"트렌드와칭 텔레그램 참여하기 (최신 소식, 자료 공유)"
think1more@gmail.com